libmemif源码分析
libmemif
memif是Mmeory Interface的缩写,memif库实现了进程间高性能数据包传输
为什么高性能?
- 共享内存实现进程间通信
- 无锁环形缓冲区 + 批量收发 + 双缓冲实现数据包传输
- epoll实现事件模式
环形缓冲区也称为循环队列
特点
- 支持多线程
- 支持0拷贝
- 支持epoll外部处理
- 支持中断(事件)模式或轮询模式
常用结构体
1 | /** \brief Memif连接参数 |
1 | /** \brief Memif 数据包缓冲区 |
常用API
1 | /** \brief Memif 初始化 |
源码分析
下文中的消息队列指的是建立socket连接后,libmemif使用单链表实现的简单队列,用于进行建立连接类的消息通讯
下文中的数据传输队列指的是建立memif连接后,libmemif使用共享内存实现的环形缓冲区,用于进行数据包的传输
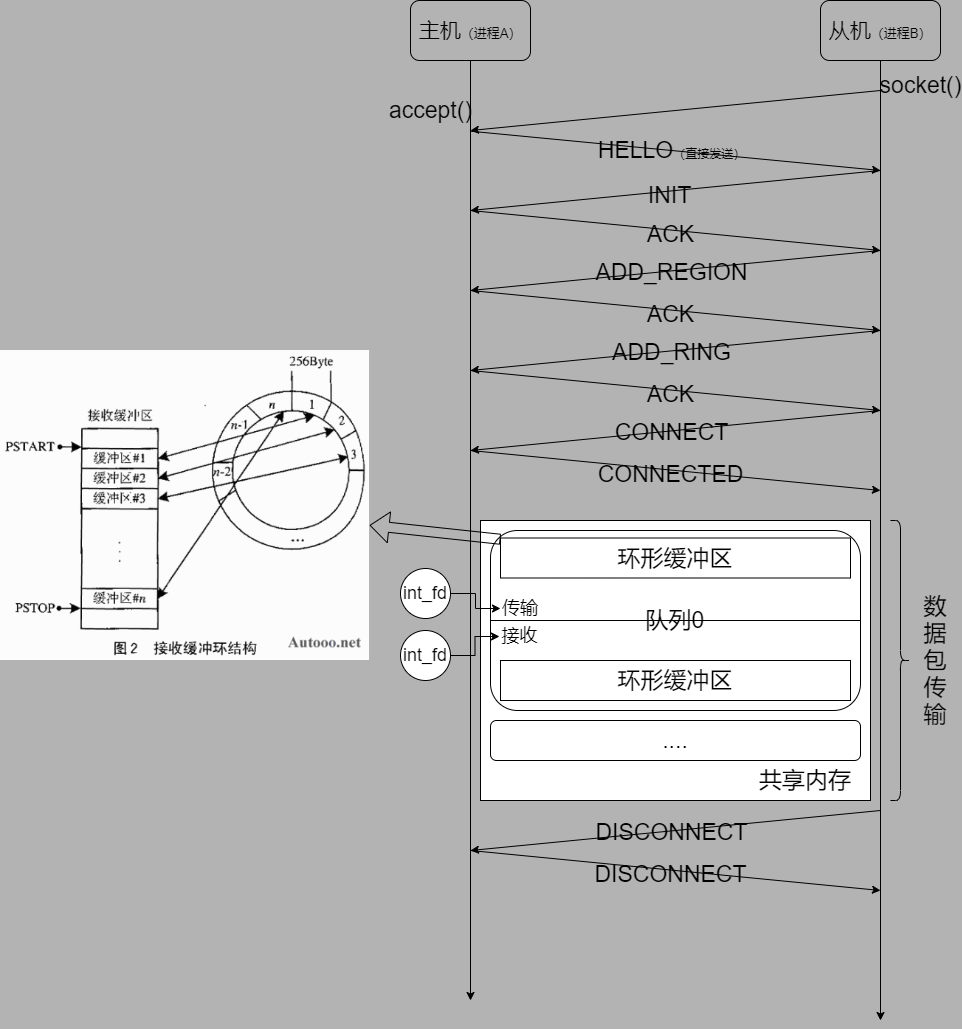
初始化memif_init流程
- 注册自定义内存管理函数
- 注册自定义epoll轮询回调函数
- 初始化连接列表、中断列表、socket列表等
- 创建定时器,并初始化为2秒(用于重连)
- 创建默认memif_socket_t结构体(注意!不是socket)
创建memif_create流程
- 将连接参数、回调函数等添加到memif_socke的interface_list里
- 如果是主机,就开始监听连接(监听到的从机socket连接添加socket_list里,并挂到epoll上)
- 如果是从机,就将连接参数添加到control_list里(由于还没连上主机,所以此时contort_list里的fd是-1),并尝试连接到主机(如果连接失败就启动定时器一直尝试重连)
请求连接memif_request_connection流程
- 创建
AF_UNIX域socket,尝试连接到主机 - 注册socket的读、写回调(关键!读回调用于与主机进行简单的通信。协商创建共享内存域、环形缓冲区等等,写回调用于发送消息队列中的消息给对端)
- 修改control_list里的fd为socket的fd,并将fd挂到epoll上(用于通知读、写回调)
- (如果连接失败就启动定时器一直尝试重连)
主机accept后流程
- 直接发送HELLO消息(不使用消息队列)
HELLO消息处理流程
- 协商队列数量、单个数据包大小。获取对端接口名等
- 初始化共享内存域和循坏队列(数据传输队列、消息传输队列)
- 接口密码(可选)消息入队
- 共享内存域、环形缓冲区的信息入队
INIT消息处理流程
- 处理接口密码(可选)入队
- ACK入队
创建数据传输队列流程
- 根据连接参数,先创建合适大小的共享内存
- 将共享内存分为2个区域,区域0存储环形缓冲区的信息;区域1存储具体的数据包内容
- 创建数据传输队列,每个数据传输队列有2个环形缓冲区:Rx和Tx
- 为每个环形缓冲区都创建一个eventfd
eventfd用于写入数据后,触发对端的中断on_interrupt回调
传送数据包memif_tx_burst过程
- 根据队列ID拿到对应的Tx环形缓冲区(下文称为ring)
- 计算掩码(用于确定数据包缓冲区在ring中的位置)
- 循环要传输的数据包
- 使用内存屏障保证所有数据包已经正确写入长度
- 触发对端的中断on_interrupt回调
接收数据包memif_rx_burst过程
- 根据队列ID拿到对应的Rx环形缓冲区(下文称为ring)
- 计算掩码(用于确定数据包缓冲区在ring中的位置)
- 循环取出数据包
- 如果是从机,在取完数据后需要重置数据包缓冲区大小
- 记录下这次已经处理完ring的索引(用于下次确定从ring的哪里开始读取数据包)
扩展知识
为啥环形缓冲区高性能?
当一个数据元素被用掉后,其余数据元素不需要移动其存储位置,从而减少拷贝提高效率
为啥循环缓冲区的大小只能是以2为底的对数?
实现环形缓冲区需要使用取模运算(用于确定头、尾指针在环中的位置)
而众所周知位运算是最快的一组运算,当然也比取模运算快
而所有以2为第的对数,都可以将取模运算转换成位运算
即:若 $ M = 2^x $且 \(x\) 为自然数,则以下公式成立 \[ M \bmod N = M\ \\\&\ (\ N\ -\ 1\ ) \]
所以8 % 7就可以写成 8 & (7 - 1),提高了运算性能
等式证明
假设$ M = 8 = 2^3 \(,那么\) M - 1 = 7 $,二进制为0000 0111b
若 $ M < 8 $, $ M = M $ , $ M = M $,等式成立
若 $ M > 8 \(,\) M = 2a+2b+2^c+... $ 比如,$ 51 = 1+2+16+32 = 20+21+24+25 $ ,求 $ 51 $时,由于7的二进制是
0000 0111b,所以2的幂只要大于等于\(2^3\)的数,与上7结果都是0,所以$ 2^4 = 0 , 2^5 \& 7 = 0, (20+21+24+25) \& (7) = 20+21=3 \(。而根据结论1,\)(20+21) \& 7 = (20+21) \(,所以\) 51 \& 7=51 $
综上得证。
为啥可以实现无锁并发?
volatile关键字内存屏障
volatile关键字阻止了编译器为了提高速度将变量缓存起来,而修改后不写回内存屏障阻止了现代CPU的乱序执行,保证在屏障之前的指令不会在屏障之后执行
这样就保证了传输数据时,每个数据包的长度都被正确写入后,再通知对端
如果不加内存屏障,可能数据、数据长度还没写完,由于CPU的乱序执行优化,就通知对端,这样读到的缓冲区内的数据就不完整
只能在单生产/单消费模式时不需要加锁同步
为啥源码中关于socket消息的结构体都有__attribute__((packed))?
这个编译指令是什么?
告诉编译器按照实际占用字节数进行内存对齐
存在的意义?
其实这里的做法和Linux内核中关于网络协议的实现一致
因为不同平台(指操作系统、编译器等)的内存对齐方式不同,如果使用结构体进行平台间的通信,就可能会有问题
举例: 假设没有使用 __attribute__((packed))
发送消息的程序是GCC编译的,xxx_msg_t结构体默认的内存对齐策略为24字节,而接受消息的程序是另一个编译器,而另一个编译器下xxx_msg_t结构体默认的内存对齐策略为32字节(只是随便举个例子),那么每个变量对应的值就不对了。
memif_ring_t里的cacheline是个什么玩意?
Cache Line是什么?
由于CPU高速缓存的存在,CPU不再是按字节访问内存,而是以64字节为单位的块(Chunk)拿取,称为一个缓存行(Cache Line)
而当你读一个特定的内存地址,整个缓存行将从主存/低速缓存换入高速缓存,以提供高速访问
这时候有大聪明要问了,为啥CPU不能直接读主存呢,多省事啊?因为CPU运行速度极快,而主存完全跟不上CPU的速度,直接读主存会拖累CPU的运行速度(CPU长时间处于等待IO状态中)
Cache Line对齐是什么?
默认情况下,结构体内存会按照数据大小对齐, 而Cache Line对齐就是将结构体的内存对齐到与Cache Line的大小一致
存在的意义?
Cache Line对齐是对CPU缓存优化的一种方式
一般来说
如果按数据大小对齐,结构体里的数据可能会跨Cache行存放,CPU读取时就需要访问多次缓存行,影响性能
而我们可以将结构体按照一个缓存行的大小(64字节)进行内存对齐
这样就可以一次将整个结构体读入Cache中,减少CPU高级缓存与低级缓存、内存的数据交换次数
但在memif_ring_t中,其实另有其他更重要的作用
在memif_ring_t里使用Cache Line对齐意义?
- cacheline0的作用
这行的意义不明,在GCC下有没有这行都一样。个人猜测应该是为了GDB调试时方便查看结构体的内存布局
- cacheline1和cacheline2的作用
1 | typedef struct |
强制head与tail不在同的Cache Line中
为什么需要将两个volatile变量存在不同的Cache Line中?
为了解决伪共享的问题
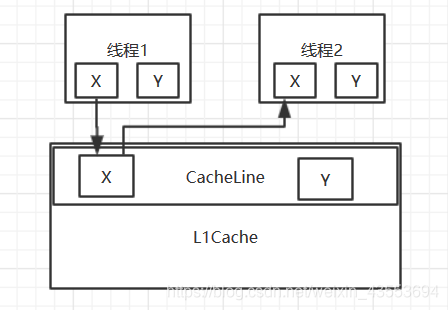
在多CPU环境下,首先明确volatile变量在某个CPU修改后,在写回时,会通知其他CPU重新读取缓存,以确保一致性
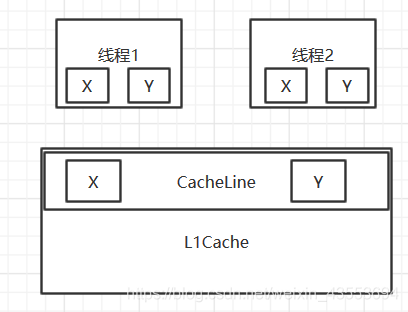
如果两个volatile变量X和Y在同一个Cache Line,而这两个变量某一个被修改时,由于volatile的特性,另一个CPU就会被通知重读缓存。这种无谓的通知就浪费了性能。这种现象就叫伪共享
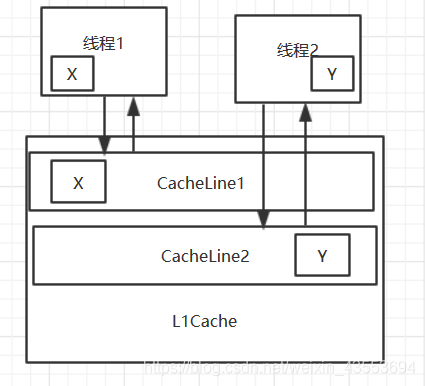
而将两个volatile的变量放到不同的Cache Line中,就不需要一直通知另一个CPU更新数据了,因为另一个CPU根本没有也不需要这个数据
Linux下查看Cache Linux大小
$ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
如何进一步提高性能?
- memif的最关键的性能瓶颈在于数据包的拷贝,所以可以尝试使用SIMD(AVX2、AVX512)指令集提高拷贝性能
- 在流量密集情况下使用轮询模式,而非中断模式,减少中断开销(实现NAPI)
- 使用自定义的内存管理模块(比如内存池)。以提高缓存命中、减低内存碎片化
- 如果你的程序中有其他模块需要使用到epoll,请使用自定义的epoll,以减少多余的内存消耗、以及多个线程epoll_wait的开销
- 实现0拷贝(直接修改接收到的数据包,再直接重新入队)
- 使用线程池实现多线程(不要开太多工作线程,一般与CPU核心数一致即可,减少CPU在线程上下文的切换成本)
epoll使用红黑树实现,提供O(logN)的查询时间复杂度,即使大量挂载也比多开几个epoll的成本(额外的CPU线程上下文切换成本、内存成本)小
常见Q&A
Q: 连接不上,抛出
Connection refused异常,或刚连就直接触发Disconnect事件A: 检查两个进程之间连接参数是否一致!比如
Socket的位置、Rx / Tx队列数是否一致等等
Q: 无法向共享内存缓冲区
memif_buffer_t中拷贝数据,抛出segmentation fault异常A: 检查是否手动为共享内存缓冲区
memif_buffer_t分配内存。注意:这里的手动分配内存不是指调用memif_buffer_alloc
Q: 连接正常,但发出去的数据对面收不到,也都不抛出异常
A: 检查对方是否正确的实现了
on_interrupt或轮询
Q: 我想用我自己的epoll(自己处理epoll事件)怎么办?
A:
memif_init时传入epoll事件的回调,可以参考/examples/icmp_responder-epoll中的实现
Q:
memif_init报错怎么办?A: 确保你的
memif_init整个进程运行时只被调用过一次